
Potenciální členové se nás často ptají na uptime a dostupnost našich serverů. Ukážeme statistiky.
Dlouhodobě měříme dostupnost na několika různých bodech naší infrastruktury a máme tak k dispozici přesná data o naší dostupnosti a o trvání jednotlivých výpadků. Zprávy z těchto měření jsou poměrně dobré.
Nejjednodušší měření představuje ping na některé naše servery. Ten dlouhodobě dosahuje hodnoty 99,986 %. To znamená, že měsíčně jsou naše servery dohromady nedostupné asi 6 minut (kalkulačka). Nezohledňuje to ovšem celkovou funkčnost všech komponent, ale jen to, že síť funguje a server odpovídá na ping.
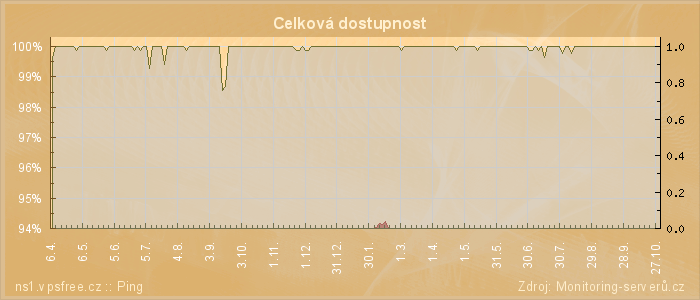
Hlubší test pak představují pravidelné dotazy na HTTP server. Ty dokáží zjistit, že funguje celá aplikační část, odpovídá databáze a souborový systém vydává data. Tam se nám daří dlouhodobě držet dostupnost na 99,875 %. Měsíčně jsou pak měřené servery nedostupné po 54 minut, což je 12 minut týdně. Je tu vidět, že každá setina procenta znamená velký posun v absolutních číslech.
Reálně se ale většina výpadků odehraje v době kratší než deset minut. Tyto krátké výpadky tvoří dohromady téměř 80 % případů. Naopak jen pět výpadků za poslední rok bylo delších než 30 minut. Není to tedy nijak dramatické, i když prostor ke zlepšení tu v každém případě je.
Dosáhnout vyšších hodnot je velmi těžké, platí tu Paretův princip, který říká, že pro dosažení 80% úspěšnosti stačí 20 % vynaložené síly. Ovšem čím víc stoupáte ke 100 %, tím strměji roste potřeba vloženého úsilí. My ovšem nepolevujeme a snažíme se v tomto ohledu dělat postupně další změny, které nám postupnými krůčky pomáhá dostupnost zvyšovat.
V současné době nám největší problém způsobuje kombinace Linuxu a ZFS. Linuxové jádro totiž není stavěné na velkou paměťovou zátěž a někdy dojde k deadlocku – Solaris s tím například problémy nemá. Protože ale intenzivně reportujeme chyby a ladíme ve spopuráci s vývojáři ZFS on Linux, podařilo se nám většinu velkých problémů vyřešit. Záseků už je teď v praxi minimum, ale ladíme dál.
Časem bychom se rádi dostali do stavu, kdy v Brně v hackerspace Base48 spustíme vlastní testovací QA cluster, který nám dovolí odhalit problémy dříve než nasadíme nové jádro do produkce. Budeme si pak udržovat vlastní sadu otestovaných komponent, u kterých si budeme jisti, že fungují a že do nich během posledního vývoje nebyla zavlečena žádná nová chyba.
chápu, ZFS a snapshoty jsou určitě návykové.
Náhodou nemáte v plánu poskytovat Solaris?
Testujeme běh KVM na vpsFree.cz a někteří uživatelé už to provozují. V KVM je možné si pak pustit libovolný systém, včetně Solarisu.